
Hace unos 6 meses estoy trabajando con Amazon AWS. Más específicamente servicios como EC2, S3, VPC y Route 53.
Mi experiencia ha sido increíble y nunca he tenido problemas, sin embargo esta semana me he topado con un error en una de las instancias de EC2.
Resulta que quise reiniciar la instancia, simple cuestión de mantenimiento. Al hacerlo, la instancia no se inició de forma correcta y tuve un error en los checks de comprobación: Status Checks 1/2.
Siendo mas detallados, la comprobación de nombre Instance Status Checks falló. Me mostraba el siguiente error: Instance reachability check failed. No tenía acceso a la consola de mi instancia EC2 y no iniciaba de forma correcta. 🙁
Fue pánico total, pues en esa instancia, estaba corriendo un servidor, administrado con Plesk, con más de 15 sitios activos.
Solucionando errores en Amazon EC2 sin acceder a la consola.
Sin acceso a la consola de una instancia, y prácticamente sin mucha información de entrada, podría parecer imposible o MUY complicada la solución, restauración o literal, resucitar nuestra instancia de EC2.
Resulta que solucionar este tipo de errores puede ser muy práctico, una vez conoces el proceso.
En mi caso, la instancia no iniciaba debido a un «Kernel Panic», en resumen: El sistema lanzó actualizaciones y la nueva versión del Kernel, causaba errores al momento de iniciar la instancia EC2.
La solución en este caso, es acceder al volumen, crear una copia, conectarlo a una instancia EC2 temporal y revertir los cambios y/o actualizaciones del Kernel.
Pero, vamos en orden. Haremos exactamente esto:
- Obtener información del error.
- Crear una instantánea/snapshot del volumen.
- Crear un nuevo volumen.
- Crear una nueva instancia EC2 temporal.
- Adjuntar volumen a instancia temporal.
- Montar volumen en el SO de la instancia temporal.
- Actualizar al Kernel predeterminado.
- Separar volumen de instancia temporal.
- Adjuntar volumen en la instancia EC2 con el error.
- Encender.
- Eliminar discos o snapshots innecesarios.
- SER FELIZ. 😉
Parece un poco extenso, pero en realidad no es un proceso muy demorado. Lo mejor, si ejecutas cada paso con cautela y dedicación, seguramente resolverás los problemas o errores en la instancia EC2 de Amazón, posiblemente ocasionados por un kernel panic.
1. Obtener información.
Lo primero es obtener información del error que está impidiendo que la instancia se inicie de forma correcta. En mi caso era el una actualización del kernel, sin embargo no siempre es lo mismo.
Desde la instancia EC2 con errores, obtén un registro del sistema o una captura de la instancia.
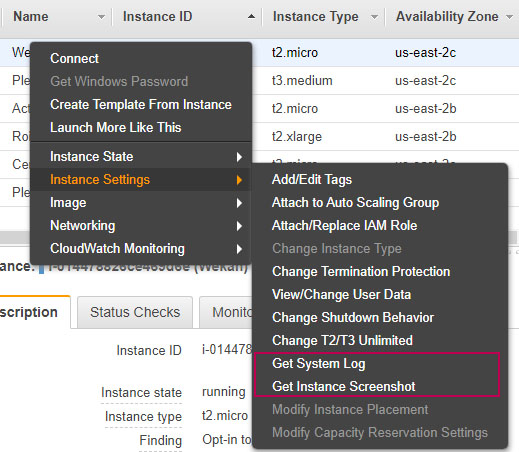
En mi caso, ambos pasos, indicaron que el error se debía a un kernel panic (Pánico en el kernel). En resumen, era un listado de errores y al final se evidenciaba la alerta por el kernel, esta alerta o error evitaba que mi instancia ec2 se iniciara de forma correcta.
Apaga la instancia, stop.
2. Crear una instantánea del volumen.
Con la instancia apagada, vaya a volúmenes, encuentre el volumen de la instancia con errores, a continuación cree una instantánea/snapshot del volumen.
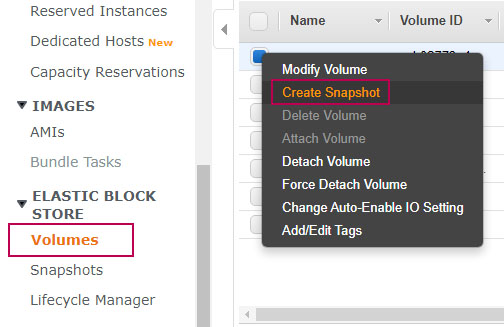
IMPORTANTE: Para evitar confusiones, asigne un valor en la columna name. Esto ayudará más adelante, para identificar nuevos volúmenes, instantáneas o cualquier recurso en AWS.
3. Crear un nuevo volumen a partir de la instantánea creada anteriormente.
Para continuar el proceso, vamos a crear un volumen del snapshot anterior.
IMPORTANTE: Asegúrate de crear el volumen en la misma zona de disponibilidad de tu instancia ec2 para poder utilizarlo sin ningún problema. Puedes ver esto en la información principal de las instancias, en mi caso es algo tipo: Availability Zone: us-east-2c.
Para crear el volumen, solo debes dar click derecho en el recién creado snapshot y pulsar en Create Volume. (Crear un nuevo volumen).
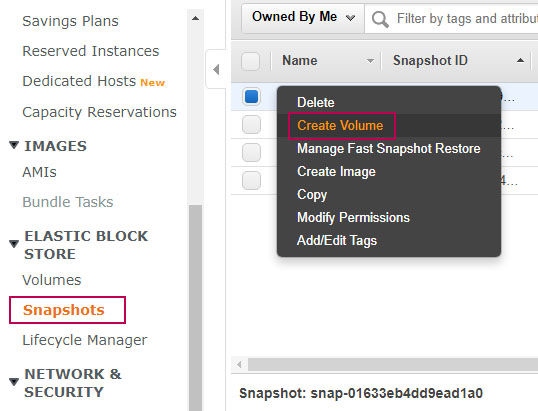
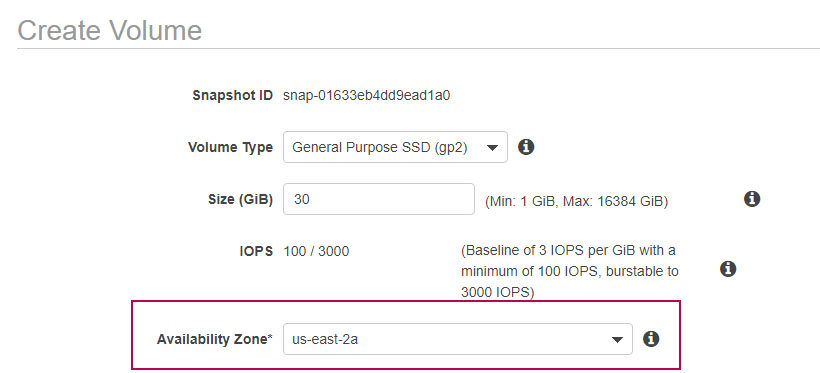
Los pasos anteriores pueden tardar, depende de distintos factores. Por favor espere hasta finalizar el proceso.
4. Crear una nueva instancia temporal.
Este paso es simple y tiene como objetivo crear una instancia temporal, a la cual nos podamos conectar sin errores. En mi caso, intentaba reparar una instancia que contenía un servidor web, implementado con Plesk en Centos 7.
Le recomiendo que cree una instancia similar a la anterior, con menos recursos, pero con el mismo tipo de sistema o finalidad.
Una vez haya terminado de crear e implementar esta nueva instancia, puede apagarla. Esto será necesario para que podamos adjuntar el volumen anterior. (El que pretendemos reparar).
Seleccione la instancia, clic derecho, detener. Espere hasta que termine el proceso.
5. Adjunte el volumen creado a la nueva instancia.
En la consola de AWS, en el menú volúmenes, clic derecho en el volumen recién creado y selecciona adjuntar volumen. Attach Volume.
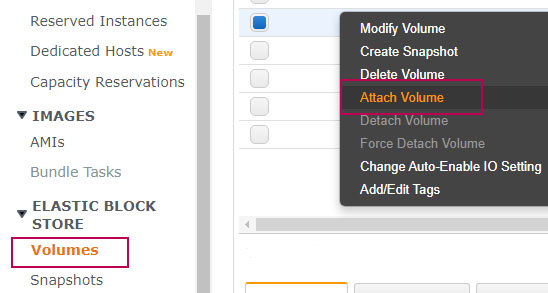
En la ventana que aparece, asegúrate de seleccionar la instancia temporal.
IMPORTANTE: En device verás algo tipo: /dev/sdf. Si al momento de iniciar la instancia tienes algún error, desconecta el volumen, vuelve a conectarlo y reemplaza /dev/sdf por el valor indicado en la alerta, ejemplo: /dev/sd1.
6. Montar volumen dentro del sistema operativo.
El objetivo acá, es hacer que el sistema operativo reconozca el volumen recién agregado, para poder manipularlo.
Ejecuta el siguiente comando:
lsblk
Deberás tener algo similar en pantalla, con los datos de los volúmenes:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 15G 0 disk
└─xvda1 202:1 0 15G 0 part /
xvdb 202:0 0 15G 0 disk
└─xvdb1 202:1 0 15G 0 part
Crea un y luego monta la partición raíz del volumen a reparar. En el ejemplo anterior, /dev/xvdb1 es la partición raíz del volumen montado. Asegúrate de estar usando el correcto. (Puedes guiarte por el tamaño del disco).
sudo mkdir /mount
sudo mount /dev/xvdb1 /mount
En este punto, ya podemos acceder a los datos de la instancia afectada. Puedes comprobarlo con el siguiente comando:
df -h
El anterior comando entregará algunos datos sobre los volúmenes de la instancia. Prefiero decir: Discos asociados y disponibles en el SO.
Antes de hacer cualquier cambio, necesitamos ejecutar los siguientes comandos:
sudo mount -o bind /dev /mount/dev
sudo mount -o bind /run /mount/run
sudo mount -o bind /proc /mount/proc
sudo mount -o bind /sys /mount/sys
Lo siguiente es poner o «trasladar» nuestra sesión en el contexto de la máquina que intentamos reparar. Solo debes ingresar en la consola:
sudo chroot /mount
7. Actualizar al Kernel predeterminado para solucionar el error de la instancia EC2.
Ahora, vamos a reemplazar el kernel/núcleo corrupto. Lo que hacemos acá de cierta forma, revertir la actualización y usar el kernel por defecto.
Ejecuta el siguiente comando para ver el kernel predeterminado actual:
grubby --default-kernel
Ejecuta el siguiente comando para tener acceso a todos los kernels o nucleos disponibles y sus índices: index=0, index=1, index=2…
grubby --info=ALL
Lo siguiente es un ejemplo de salida del comando anterior:
[root@ip-10-10-1-111 ~]# grubby --info=ALL
index=0
kernel="/boot/vmlinuz-4.18.0-147.3.1.el8_1.x86_64"
args="ro console=ttyS0,115200n8 console=tty0 net.ifnames=0 rd.blacklist=nouveau crashkernel=auto $tuned_params"
root="UUID=a727b695-0c21-404a-b42b-3075c8deb6ab"
initrd="/boot/initramfs-4.18.0-147.3.1.el8_1.x86_64.img $tuned_initrd"
title="Red Hat Enterprise Linux (4.18.0-147.3.1.el8_1.x86_64) 8.1 (Ootpa)"
id="2bb67fbca2394ed494dc348993fb9b94-4.18.0-147.3.1.el8_1.x86_64"
index=1
kernel="/vmlinuz-0-rescue-2bb67fbca2394ed494dc348993fb9b94"
args="ro console=ttyS0,115200n8 console=tty0 net.ifnames=0 rd.blacklist=nouveau crashkernel=auto"
root="UUID=a727b695-0c21-404a-b42b-3075c8deb6ab"
initrd="/initramfs-0-rescue-2bb67fbca2394ed494dc348993fb9b94.img"
title="Red Hat Enterprise Linux (0-rescue-2bb67fbca2394ed494dc348993fb9b94) 8.1 (Ootpa)"
id="2bb67fbca2394ed494dc348993fb9b94-0-rescue"
index=2
kernel="/boot/vmlinuz-4.18.0-80.4.2.el8_0.x86_64"
args="ro console=ttyS0,115200n8 console=tty0 net.ifnames=0 rd.blacklist=nouveau crashkernel=auto $tuned_params"
root="UUID=a727b695-0c21-404a-b42b-3075c8deb6ab"
initrd="/boot/initramfs-4.18.0-80.4.2.el8_0.x86_64.img $tuned_initrd"
title="Red Hat Enterprise Linux (4.18.0-80.4.2.el8_0.x86_64) 8.0 (Ootpa)"
id="c74bc11fb3d6436bb2716196dd0e7a47-4.18.0-80.4.2.el8_0.x86_64"
El núcleo corrupto actual está en la posición 0 (cero) en la lista. El último kernel estable está en la posición 1.
Es importante obtener la información correcta sobre el kernel por defecto. Es suficiente lo anterior, pero adicional, puedes ejecutar el siguiente comando:
yum list installed | grep kernel
Obtendrás el nombre exacto de los kernels del sistema. En este caso, el primero, es original o por defecto.
IMPORTANTE: Ten en cuenta la ruta del kernel que deseas establecer como predeterminado para la instancia. En el ejemplo anterior, donde vimos los indices y detalles de cada uno… La ruta para el kernel con indice 2 es:
/boot/vmlinuz-0-4.18.0-80.4.2.el8_1.x86_64.
Ejecuta el siguiente comando para cambiar el kernel predeterminado de la instancia:
grubby --set-default=/boot/vmlinuz-4.18.0-80.4.2.el8_1.x86_64
IMPORTANTE: Debes reemplazar vmlinuz-4.18.0-80.4.2.el8_1.x86_64 con el nombre y número de versión del kernel a restaurar.
Para verificar que el procedimiento anterior funcionó, ejecuta el siguiente comando:
grubby --default-kernel
Cierre su sesión actual y desmote.
exit
sudo umount /mount/dev
sudo umount /mount/run
sudo umount /mount/proc
sudo umount /mount/sys
sudo umount /mount
8. Separe el volumen de la instancia temporal.
En este punto, vamos a volúmenes, ubicamos el volumen creado para este proceso, clic derecho, Detach Volume.
IMPORTANTE: Verifica que la instancia original, no tenga ningún volumen asociado. Puesto que le asignaremos el nuevo y reparado volumen.
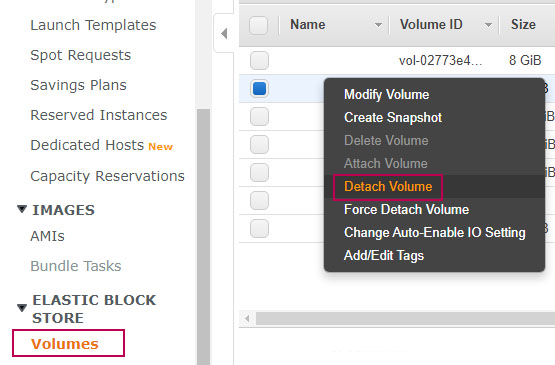
Confirme el proceso y espere hasta que esté completo.
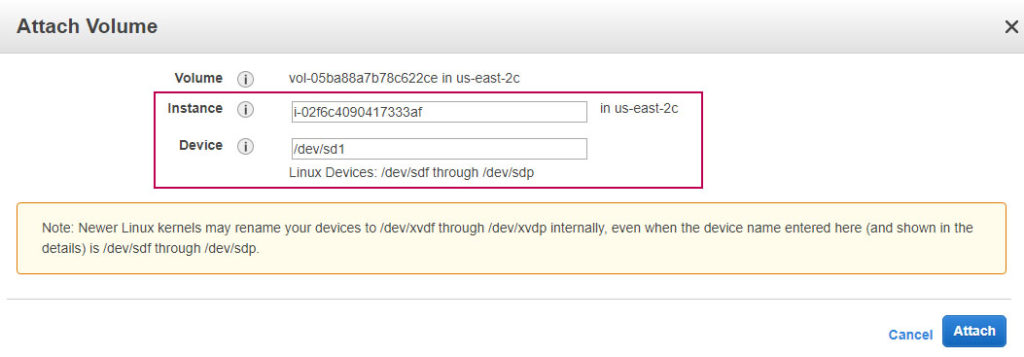
9. Adjuntar volumen a instancia original.
Momento de ajuntar el volumen recién reparado a la instancia original.
IMPORTANTE: Recuerda que no debe estar asociado a ninguna instancia. Que la instancia original no debe tener volúmenes asociados.
En la ventaba que se abre, en la ruta del disco primario (device) debes poner dev/sda1. Si no funciona puedes probar con dev/sda, /dev/xvda… Siempre puedes obtener el valor exacto al momento de iniciar la instancia y ver la alerta con posible error asociado a la ruta del disco.
10. Encender la instancia original.
Este es el momento más fuerte y emocional.
En mi caso, tardó algunos minutos, pero inició de forma exitosa. Recuerda inspeccionar el registro de errores y tomar capturas de la consola, para estar atento a cualquier posible error.
En caso de fallar, puedes realizar le proceso nuevamente o intentar una solución diferente.
Sin posibilidad de acceso directo a la instancia, el proceso se hace un poco más complicado, pero no imposible.
Se trata de acceder al volumen e intentar solucionar el error que impide iniciar la instancia.
¿Lograste solucionar el error de tu instancia EC2 de Amazon AWS?
Mucho amor, ¡Recuerda compartir! 😉
CC.